Reinforcement Learning shows me the fastest way around my university
A RL experiment on finding the optimal way to cross a street
Published: 8. October 2025

A pedestrian crossing light in Berlin
Image from Jos van Ouwerkerk
TLDR;
A simple RL project, learning the optimal ways around campus.
A educational project on using tabular Q-Learning model on a newly created environment.
github.
Do you know this feeling where you are unsure if you should cross the street now or continue walking
in the right direction and take a crossing a little bit later to save some time. How do you know if
the way you take is the optimal way? Is there an optimal strategy?
As I wanted to get some traction with Reinforcement Learning, I modelled my most common walking routes
around my university to find the optimal paths. To be frank, this project is a rather
simple and straightforward problem and most likely wouldn’t necessities an agent to maneuver through it.
The main motivation was for me to learn and get some more traction with RL.
The environment
The most common places around university for me are the library, the castle, the cafeteria, the café and the grocery store. On Google maps this looks like this:
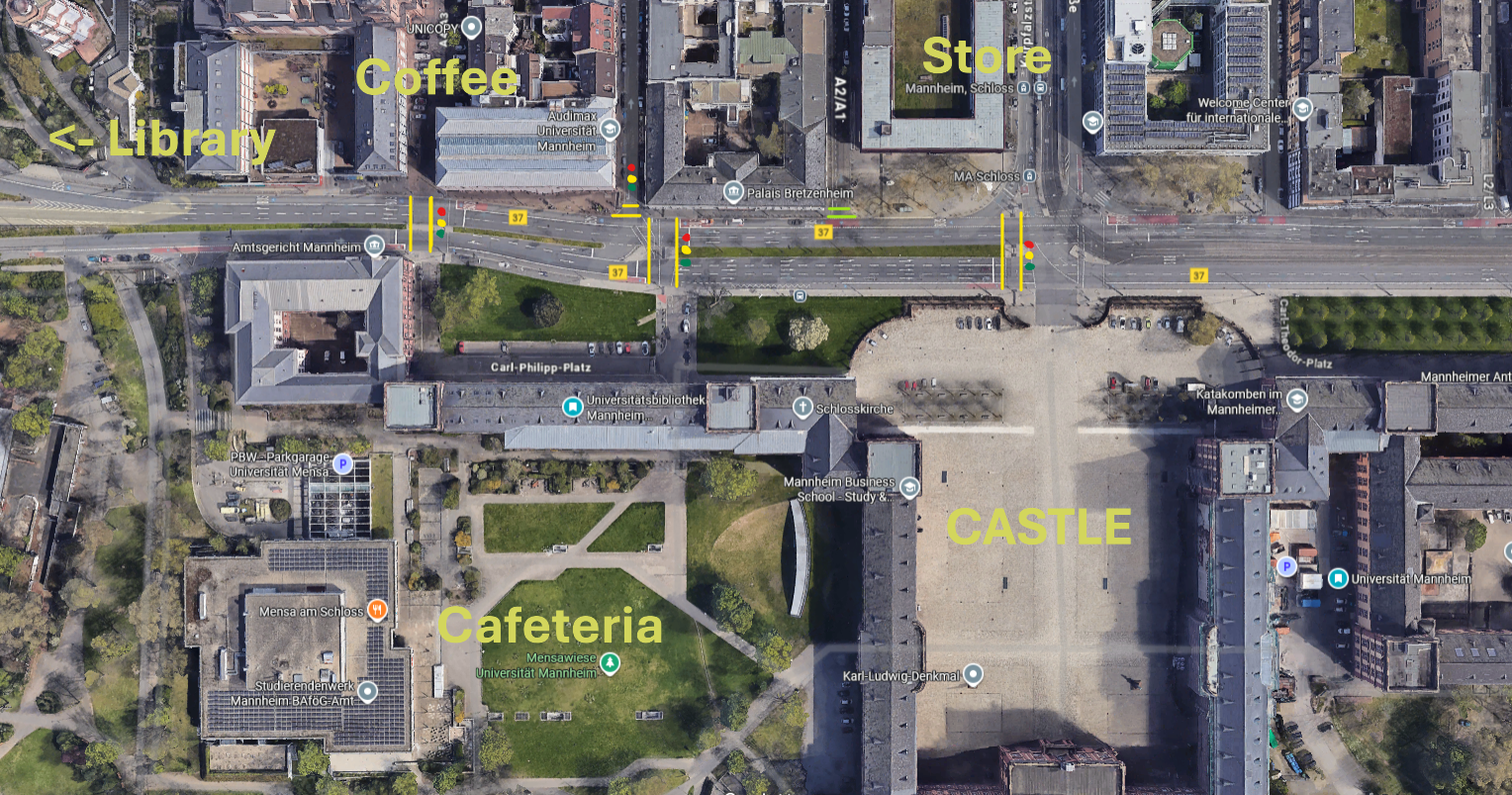
Google Maps Images of the environment with annotated locations
All the locations are located on two sides of a big road. There are three traffic lights which allow you to cross the street
along it. There is further a small traffic light on a horizontal crossing, right beside the café and another horizontal crossing
without any lights between the store and the coffee shop.
I modelled the environment (env) in the RL library Gymnasium and created a simple visualization with pygame.
The env has a shape of (28 x 3) blocks. Where each block is a position where something can be placed.
The agent can only move at the first and third row. The vertical pedestrian crossing lights are in the second row.
At every epsiode the agent starts at one of the five locations and tries to get to the target location which is also chosen
from the five locations. The positions of the traffic lights and the crossing are fixed.
A major simplification comes in the working logic of the traffic lights:
They all follow a sequentiel cycle which is not even close to the timing in real life.
At the beginning of an episode, the current step of the cycle is determined by random.
There is no action for the agent to interact with the traffic lights. He can only cross the street when they are green.

Pygame Environment
Agent moves towards coffee shop
The state space consists of: Agent position (only 1st and 3rd row accessible) x
target position (5 distinct) x traffic light positions (fixed) x
status of traffic lights and crossing (binary) = 8960 states.
The action space allows the agent to move Up, Down, Left, Right and Wait. (5)
The state-action space contains in total 8960 * 5 = 44.800 state-action pairs.
For the reward function I tested different approaches: Getting rewards for moving closer to the target,
crossing the street and reaching the target. I also tested negative rewards for illegally aiming
to cross the street and moving away from the target. In the current version, I simplified it to
provide a small penalty for each step in time where the target is not reached.
The agent
The agent uses tabular Q-learning as the state-action space is still reasonable small. The agent uses a high learning rate of 0.1, a linear epsilon decay till reaching a minimum of 0.05 in exploration. The agent is implemented in plain python and uses a nested dictionary to store the state-action value function.
Training
As ever increasing training runs with up to 10M episodes took a decent amount of time, I ported the training routine inside a docker container and run it on this server. Surprisingly, I achieve more iterations per second when training inside the docker container on this server, then if I run it directly on my personal laptop. Howver, my laptop has better performance stats then the VPS here. I have no explaination for this yet.
Results
The agent can maneuver through the environment and reaches all targets.
However, the agent sometimes jitter around when waiting in front of a crossing. From a human perspective,
this seems off, but as the agent isn't penalized for moving while waiting, he apparently does so.
The subsampled metrics pictured below show a decent training progress, where rewards are consistently getting
better, the efficiency increases with shorter episode lenghts and the training error plateaus indicating
a somehow stable policy.
While further finetuning of the reward function and hyperparameter tuning might lead to better results, these aspects are not considered in this short
fun project.
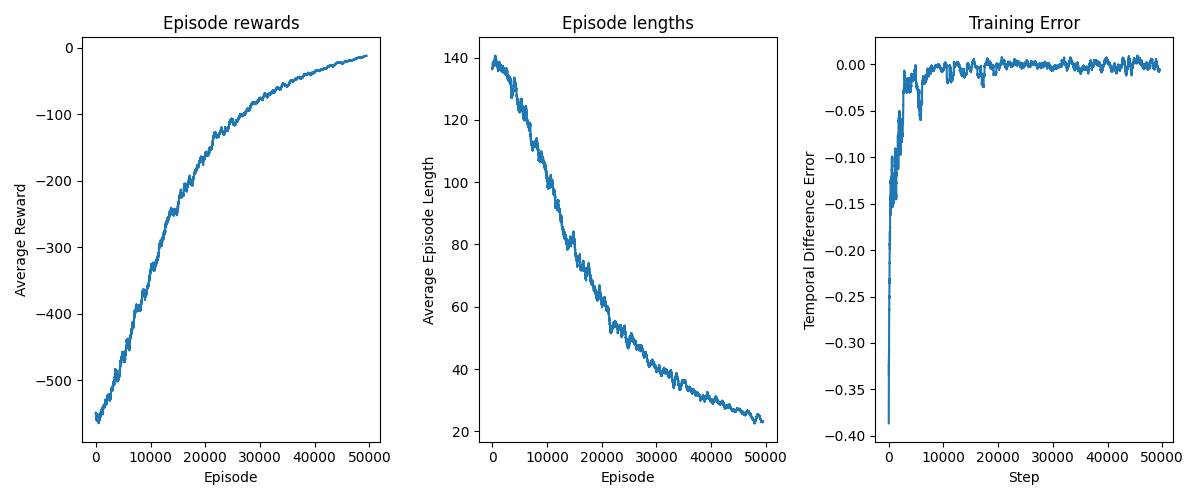
Training Metrics on rewards, lenghts and training error
Learnings
Throughout the project I learned a lot about the practical implementations of Reinforcement Learning Algorithms and about constructing environments with Gymnasium.
- Weird behavior of the agent could often be explained by a ill defined reward function: At one point, when the agent waited in front of a crossing he continously moved one step towards the target and then back till the crossing light turned green and he continued his way. The reason for that was, that the env gave a reward for moving towards the target, but no penalty for moving away from it. So instead of waiting and doesn't get any reward the agent showed this unintended behaviour.
- I continously changed the env, after increasing the size of the env I got extremly bad results. This showed me that the size of the state-action space, at least for this model is extremly sensitive. Therefore being able to compress the space or making it size invariant can, from a computational perspective, be very helpful.
Conclusion
Even such simple scenarios as crossing a street opens huge spaces for modelling and tinkering in Reinforcement Learning.
Constructing environments, designing reward functions and choosing a decent learning algorithm is not only a
mere technical interesting undertaking but also a highly educational one.
By looking at the world through the lens of reinforcement learning we find a somehow persuasively simple
methodology to try to explain the world and how learning in it works.
This project offered me a simple and practical introduction to Reinforcement Learning.
Thank you for reading my second article!
If you have any feedback, I'd love to read it!
Send me a mail!
External Link and Mail icon by Icons8